Building an Aviation Data Platform: From Raw Telemetry to Lakehouse
by Ondrej Grünwald, Founder / CEO
The SkyTrace post covered the telemetry UI — the map, the WebGL rendering, and how the frontend stays fast. This post is about everything underneath it.
SkyTrace is the operational surface. The data platform is the foundation it runs on. Without the platform, there is no replay, no historical analysis, no curation pipeline, and no way to serve both real-time queries and batch analytics from the same data.
This post covers how the platform is built, what tradeoffs shaped it, and why a lakehouse architecture turned out to be the right fit for aviation telemetry — not just at our scale, but as a pattern that maps well to how aviation organizations are starting to think about their own data infrastructure.
The platform is not a monolith with a database behind it. It is a lakehouse with two deployment modes, three processing layers, and a strict separation between hot-path and analytical workloads.
This post covers ingest, raw landing, silver/gold curation, the hot path, orchestration, and why the same raw layout runs on both a full Kafka stack and a lightweight JetStream edge deployment.
1. Why a Lakehouse for Aviation
Aviation data has a few properties that make traditional database-first architectures break down quickly.
Volume and velocity are asymmetric. ADS-B receivers produce continuous position updates — tens of thousands of messages per hour from a single receiver, each with sub-second timing requirements for live tracking. But the analytical questions (fleet patterns, anomaly investigation, maintenance correlation) need months or years of history. A single database cannot serve both workloads well.
The raw signal is the most valuable asset. Once a telemetry event is gone, it is gone. Normalization and aggregation are useful, but they destroy information. When an investigation six months later needs the original receiver timestamp, the raw squawk code, or the exact altitude before a rounding step, you need the raw data. A lakehouse keeps the raw layer intact and builds derived layers on top.
Replay is a first-class requirement. Aviation operations — incident review, procedure validation, training — depend on replaying exact sequences of events. This is not a "nice to have" analytics feature. It is a core operational need that shapes how data is stored and partitioned.
Multiple consumers need different views. A real-time cockpit display needs the last 60 seconds of validated positions. An analyst needs curated, deduplicated records partitioned by time. A maintenance system needs correlated sensor and schedule data. One storage model cannot serve all of these efficiently.
The lakehouse pattern — raw landing in object storage, structured layers built on top, query engines attached to open table formats — fits all of these constraints. And it is the same pattern that major aviation organizations are adopting as they move toward cloud-native data infrastructure.
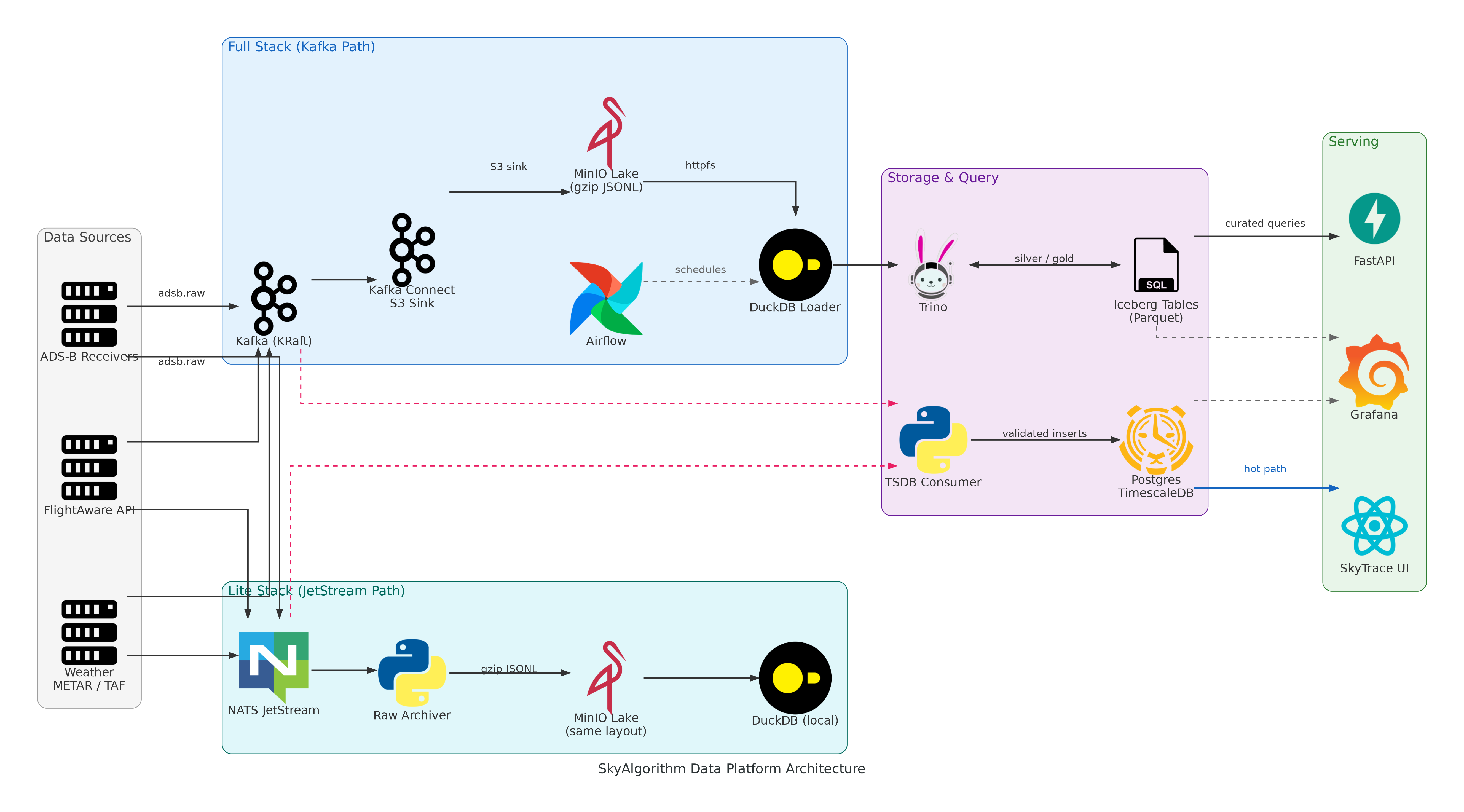
End-to-end platform architecture — from ingest sources through dual processing paths to storage and serving.
2. The Two Deployment Profiles
The platform runs in two modes that share the same raw data layout.
Full stack
Full stack uses Kafka for durable, replayable message transport. Kafka Connect writes raw data to MinIO with zero custom code. Trino queries Iceberg tables in the lakehouse. Airflow orchestrates hourly loading and curation. Postgres backs the Iceberg catalog, Airflow metadata, and the TimescaleDB hot-path store.
The TSDB consumer reads directly from Kafka in parallel and writes validated events to TimescaleDB for real-time queries — this hot path runs alongside the lakehouse path, not in series.
Components: Kafka (KRaft), Kafka Connect, MinIO, Iceberg REST, Trino, Airflow, Postgres/TimescaleDB, DuckDB loader.
Lite stack
Lite stack replaces Kafka with NATS JetStream and drops Airflow. A custom raw archiver writes to MinIO with the same Hive partition layout as Kafka Connect, so raw data from either mode can be loaded by the same downstream tooling.
This is the profile that runs on a Raspberry Pi or a developer laptop. Same data shape, same queries, smaller footprint.
Why this matters: raw data collected in lite mode can be bulk-loaded into the full stack without transformation. The partition layout is the contract, not the message bus.
3. Ingest: Normalized Events from Multiple Sources
The ingest layer runs async adapters that normalize heterogeneous sources into a common message schema before publishing.
ADS-B ingest
ADS-B adapters (OpenSky API, readsb receivers) produce a normalized event:
# Core fields — always present
source: str # "opensky" | "readsb"
icao: str # lowercase 6-hex, e.g. "3c6752"
timestamp: float # epoch seconds, event time
# Position and state — when available
lat: float
lon: float
alt_baro: float # feet
gs: float # knots
track: float # degrees
vs: float # feet per minute
on_ground: bool
callsign: str
squawk: strThe schema enforces ICAO normalization (lowercase hex), converts OpenSky meters/m·s⁻¹ to aviation units (feet/knots/fpm), and derives timestamps from receiver-reported seen_pos offsets when the source does not provide a clean event time.
Each adapter runs on its own polling interval — 30 seconds for OpenSky, 10 seconds per readsb receiver — and publishes to Kafka topic adsb.raw or JetStream subject adsb.raw.
FlightAware ingest
The FlightAware adapter polls the AeroAPI for airport flight schedules within a configurable time window. It normalizes arrivals, departures, and scheduled flights into a common record with snapshot time, airport code, identifiers (FA flight ID, ICAO, IATA), statuses, and scheduled/actual gate and runway times.
Published to flightaware.airport.v1. The topic naming convention (skyalgorithm.<domain>.<entity>.<version>) is designed for adding future sources without collisions.
Weather ingest (METAR and TAF)
A combined weather producer runs METAR and TAF adapters concurrently. METAR observations are parsed from raw and decoded text into a structured schema with station coordinates, wind speed, visibility, temperature, dew point, pressure, and sky conditions. TAF forecasts are parsed from raw TAF text with validity windows extracted from the header.
Both publish to skyalgorithm.aviation.weather.v1 and are stored in dedicated TimescaleDB hypertables (metar_observations, taf_forecasts) for hot-path querying alongside flight telemetry.
Message bus abstraction
A shared message_bus module selects Kafka or JetStream based on configuration. Kafka publishes use send_and_wait for durability guarantees. JetStream publishes to subjects with stream auto-creation. The adapters do not know which transport they are using.
4. Raw Landing: The Partition Contract
Raw data lands in MinIO as gzip-compressed JSONL files, partitioned by ingestion time:
lake/topics/adsb.raw/year=2026/month=03/day=15/hour=14/
part-1710511200-a1b2c3d4.json.gz
part-1710511200-e5f6g7h8.json.gz
Full stack path
Kafka Connect S3 sink writes directly to MinIO. Configuration is declarative — topic routing, flush interval, partition format. No custom code handles the raw landing.
Lite stack path
The JetStream raw archiver buffers messages and flushes to MinIO based on batch size (5,000 messages for ADS-B), byte limits (20 MiB per file), or idle timeout (15-minute pull intervals). Partition keys are derived from ingestion time, floored to configurable intervals (60 minutes for ADS-B).
Messages are acknowledged only after successful MinIO writes. Failed writes trigger exponential backoff. The archiver adds ingest_topic and ingest_ts metadata to each record for traceability.
The key design constraint: both paths produce the same directory layout, the same file format, and the same partition scheme. Everything downstream — loaders, curators, ad-hoc queries — works identically regardless of which path produced the data.
5. The Lakehouse Layers
Bronze: raw in MinIO
The raw JSONL files in MinIO are the bronze layer. They are immutable, append-only, and partitioned by ingest time. This is the system of record. Nothing downstream modifies raw data.
Silver: Iceberg tables via DuckDB and Trino
The DuckDB loader reads raw partitions using httpfs and read_json_auto, casts and normalizes types, derives event-time partition columns from the timestamp field, and inserts into Iceberg tables via Trino.
CREATE TABLE iceberg.aviation_silver.adsb_clean (
timestamp TIMESTAMP,
received_at TIMESTAMP,
source VARCHAR,
icao VARCHAR,
callsign VARCHAR,
lat DOUBLE,
lon DOUBLE,
alt_baro DOUBLE,
gs DOUBLE,
track DOUBLE,
vs DOUBLE,
on_ground BOOLEAN,
squawk VARCHAR,
-- Event-time partitions derived from timestamp
event_year INTEGER,
event_month INTEGER,
event_day INTEGER,
event_hour INTEGER,
-- Ingest-time partitions from raw layout
year INTEGER,
month INTEGER,
day INTEGER,
hour INTEGER
)
WITH (
format = 'PARQUET',
partitioning = ARRAY[
'event_year','event_month','event_day','event_hour'
]
);The silver table retains both ingest-time and event-time columns. This is deliberate — it allows tracing any curated record back to the raw partition it came from, which matters for debugging and reprocessing.
The loader handles schema drift (logging type mismatches between raw and target), creates tables automatically when they do not exist, and supports both append mode (hourly loads) and replace mode (controlled backfills that delete matching partitions before insert).
Gold: curated and deduplicated
Silver-to-gold curation runs per-partition MERGE operations:
-- ADS-B: dedup by (timestamp, icao, rounded position)
-- keeps latest by received_at / ingest_ts
MERGE INTO aviation_gold.adsb_curated AS target
USING (
SELECT *, ROW_NUMBER() OVER (
PARTITION BY timestamp, icao,
round(lat, 4), round(lon, 4)
ORDER BY received_at DESC
) AS rn
FROM aviation_silver.adsb_clean
WHERE event_year = ? AND event_month = ?
AND event_day = ? AND event_hour = ?
) AS source
ON target.event_time = source.timestamp
AND target.icao = source.icao
WHEN MATCHED THEN UPDATE ...
WHEN NOT MATCHED THEN INSERT ...The gold ADS-B table is partitioned by hour(event_time) — coarser than silver, because curated data is queried by time range, not reprocessed by ingest partition.
FlightAware curation follows the same pattern with a different dedup key: (snapshot_time, airport, flight_key, record_type), split per (year, month, day, hour, airport) partition to stay within Trino writer limits.
Iceberg maintenance
A daily maintenance job expires old snapshots (90-day retention), removes orphan files (7-day cutoff), and runs optimize to compact small files in silver and gold tables. This keeps query performance stable as the table grows and prevents MinIO from accumulating unreferenced objects.
6. The Hot Path: TimescaleDB
Not every query can wait for batch processing. The live map in SkyTrace needs the last 60 seconds of validated positions with sub-second latency. The hot path serves this.
A dedicated TSDB consumer reads from Kafka or JetStream, validates each message against the schema (invalid records route to a dead-letter topic), and inserts into TimescaleDB hypertables:
CREATE TABLE aviation_stream.adsb_messages (
ts TIMESTAMPTZ NOT NULL,
icao TEXT NOT NULL,
callsign TEXT,
lat DOUBLE PRECISION,
lon DOUBLE PRECISION,
alt_baro DOUBLE PRECISION,
gs DOUBLE PRECISION,
track DOUBLE PRECISION,
vs DOUBLE PRECISION,
receiver TEXT,
source TEXT NOT NULL,
received_at TIMESTAMPTZ NOT NULL DEFAULT now(),
PRIMARY KEY (ts, icao)
);
-- Daily chunks, 365-day retention, compression after 30 days
SELECT create_hypertable('adsb_messages', 'ts',
chunk_time_interval => INTERVAL '1 day');
SELECT add_retention_policy('adsb_messages',
INTERVAL '365 days');Compression segments by icao — queries for a specific aircraft's recent track scan a narrow time range within compressed chunks. The retention policy drops data older than a year; anything needed beyond that lives in the lakehouse.
The hot path and the lakehouse are not redundant. They serve different query patterns:
- Hot path: "where is aircraft 3C6752 right now?" (last N seconds, single key)
- Lakehouse: "show all flights through LKPR airspace on March 15" (hours/days, full scan)
Both are populated from the same ingest stream. Neither depends on the other.
7. Orchestration
Airflow runs the batch processing on the full stack:
- Hourly loaders (
duckdb_loader_readsb_hourly,duckdb_loader_flightaware_hourly): fire at HH:10, load the previous hour's raw partitions into silver Iceberg tables - Hourly curators (
adsb_curator_daily,flightaware_curator_hourly): fire at HH:30, MERGE the previous hour's silver into gold with dedup rules - Daily maintenance (
iceberg_maintenance_daily): runs at 03:20 UTC, expires snapshots, cleans orphans, optimizes file sizes
All DAGs use DockerOperator to run the DuckDB loader image inside the platform's Docker network. Backfills are supported via environment overrides — JOB_FILE_GLOB for loaders, CURATE_WHERE for curators — without modifying DAG code.
On the lite stack, these jobs can be run manually or on cron. The loader is the same binary with the same configuration. Airflow is a scheduling convenience, not a dependency.
8. Why This Architecture Fits Aviation
The lakehouse pattern is not unique to SkyAlgorithm. It is emerging as the standard approach for aviation data platforms, and for good reason.
Open table formats solve the vendor lock-in problem. Aviation organizations operate across decades-long timescales. Data collected today needs to be queryable in ten years. Iceberg (or Delta Lake, or Hudi) over Parquet on object storage means the data is not locked into a proprietary database. Trino, Spark, DuckDB, Snowflake — any engine that reads Iceberg can query it.
Object storage scales independently of compute. MinIO on-prem, S3 in the cloud, or a hybrid — the raw layer scales by adding storage, not by upgrading a database cluster. For aviation organizations sitting on terabytes of historical ACARS, ADS-B, METAR, and maintenance data, this is a meaningful operational advantage.
The medallion pattern (bronze/silver/gold) maps naturally to aviation data governance. Raw telemetry is preserved as-is (bronze). Cleaned, type-safe records with derived partitions are queryable for analysis (silver). Deduplicated, business-logic-applied records are ready for operational use (gold). Each layer has clear ownership, clear lineage, and clear reprocessing paths.
Dual deployment profiles address the edge-cloud reality. Aviation data is generated at the edge — on aircraft, at airports, from ground receivers. Not everything can or should flow through a central cloud pipeline in real time. A platform that runs the same data layout on a Raspberry Pi and on a full Kafka/Trino cluster means edge-collected data integrates without transformation. This is not a theoretical concern — it is how ADS-B ground stations actually work.
9. What I Would Do Differently
Add schema registry earlier. The current system uses Pydantic validation at ingest and tolerates schema drift at load time. A schema registry (Confluent or Apicurio) would formalize contracts between producers and consumers and catch breaking changes before they hit the lake.
Build the API surface sooner. The platform has a minimal read-only API over Trino for curated data. A richer API — covering both hot-path and lakehouse queries, with proper pagination and filtering — would make the platform more useful to downstream consumers earlier.
Invest in observability from the start. The platform has health checks and Grafana dashboards, but no structured metrics pipeline (Prometheus) or distributed tracing. For a system with this many moving parts, observability should be a day-one concern, not an add-on.
NOTAM integration and richer weather correlation. Weather ingest (METAR observations, TAF forecasts) is already running and stored in TimescaleDB alongside telemetry. The next step is correlating weather and telemetry at query time — and adding NOTAMs and airspace restrictions to the operational picture. These are among the first data sources that aviation organizations want when they start building their own lakehouse.
10. Where This Goes Next
The current platform handles ADS-B, FlightAware, and weather (METAR/TAF). The architecture is designed for more:
- Maintenance records correlated with telemetry for predictive analysis
- NOTAM and airspace data enriching the operational picture
- Weather-telemetry correlation at query time across the hot path and lakehouse
- ML feature stores built on gold-layer tables, versioned alongside the curation pipeline
The lakehouse is not the product. SkyTrace is a product. Predictive maintenance support is a product. The lakehouse is the foundation that makes those products possible — and makes the next product possible without rebuilding the data layer.
That is the real argument for building a platform instead of building an application with a database behind it.